


L'intelligibilità del parlato
- 03 Gen, 2019
- Consigli , Come fare per...

In questo articolo presentiamo alcuni fatti sull'intelligibilità del parlato e, soprattutto, su come conservarlo.
Sintesi
La lingua viene dalla parola parlata. Quindi, quando si registra la voce, si dovrebbe sempre considerare l'intelligibilità del parlato.
L'aria passa le corde vocali e crea il suono. Controllando le corde vocali il livello e il tono della voce possono variare. Influenzando le cavità sopra le corde vocali (faringee, orali, nasali), il filtraggio viene aggiunto allo spettro vocale.
Cambiando lo sforzo vocale cambia sia il livello che lo spettro di frequenze del suono della voce. Anche il tono della voce cambia con lo sforzo vocale. Gridare suona diverso dal parlare con una voce casuale.
Durante la registrazione, scoprirai che i picchi del segnale acustico sono molto più alti rispetto all'RMS o al livello medio. Assicurati che tutti i picchi sopravvivano attraverso la catena di registrazione.
Nelle lingue non tonali-soprattutto le latine- le consonanti sono importanti. Le consonanti (f, p, s, t, ecc.) Si trovano prevalentemente nell'intervallo di frequenza superiore a 500 Hz. Più specificamente, nell'intervallo di frequenze 2 kHz-4 kHz.
Noi percepiamo la voce come naturale e con la massima intelligibilità quando siamo a circa 1 metro davanti alla persona che parla. Stare di lato o dietro la persona riduce la naturalezza e l'intelligibilità.
In realtà, la voce aumenta lo spettro in quasi tutte le altre posizioni rispetto a quando ci avviciniamo alla persona che parla con il nostro orecchio - o microfono.
Ogni posizione sulla testa o sul petto ha il proprio colore sonoro - o timbro. Ad esempio, lo spettro del parlato registrato sul petto di una persona normalmente manca di frequenze nell'intervallo importante di 2-4 kHz. Ciò si traduce in una ridotta intelligibilità del parlato. Se il microfono non compensa questo, dovresti apportare correzioni con un equalizzatore.
Quindi, quando si posiziona un microfono, sii consapevole di questi problemi. Preparati a scegliere il microfono giusto progettato per l'uso nella posizione in cui lo stai posizionando. Altrimenti, preparati a compensare (equalizzare) per ottenere il suono corretto.
1. La voce come sorgente sonora acustica
La voce come fonte sonora è importante da capire. Mentre la lingua può essere qualcosa che i gruppi di persone hanno in comune, il suono e il carattere della voce sono individuali da persona a persona. Allo stesso tempo, il parlato, considerato come un segnale acustico, è il tipo di suono che ci è più familiare.
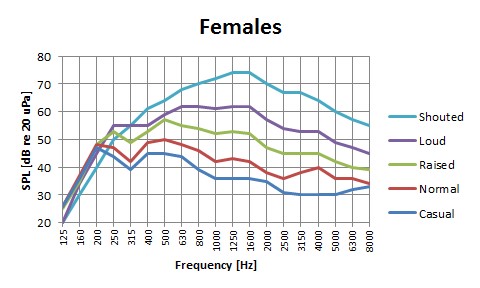
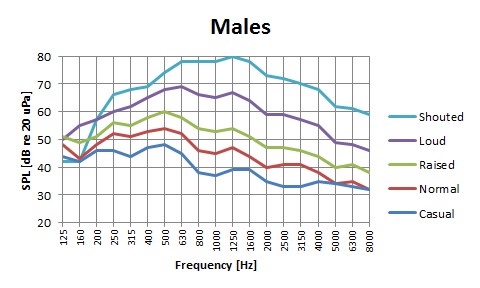
Gli sforzi vocali variano; da un sussurro sommesso a un forte urlo. È difficile assegnare un numero fisso a livello di voce, poiché questo è individuale da persona a persona. I valori nella tabella sottostante indicano il livello di voce medio ponderato A del discorso di un adulto.
Vale la pena notare che la capacità di comprendere la parola è ottimale quando il livello del discorso corrisponde al livello del parlato normale a una distanza di 1 metro. In altre parole, un livello di pressione sonora di circa 55-65 dB re 20 μPa. (In questo caso, “re” significa “con riferimento a.”; Il riferimento è il più debole livello di pressione sonora che è udibile)
Livello del parlato [dB re 20 μPa] | ||||
Distanza di ascolto [m] | Normale | Sollevato | Forte | Grido |
0.25 | 70 | 76 | 82 | 88 |
0.5 | 65 | 71 | 77 | 83 |
1.0 | 58 | 64 | 70 | 76 |
1.5 | 55 | 61 | 67 | 73 |
2.0 | 52 | 58 | 64 | 70 |
3.0 | 50 | 56 | 62 | 68 |
5.0 | 45 | 51 | 57 | 63 |
Livello medio della voce in funzione della distanza di ascolto / registrazione. C'è una differenza di circa 20 dB tra il parlato normale e l'urlo.
Fattore di cresta
Si noti che ogni livello presentato nella tabella è un livello RMS mediato e non un livello di picco. In genere, i picchi sono 20-23 dB sopra il livello RMS. Il rapporto tra il livello di picco e il livello RMS è chiamato fattore di cresta. Questo fattore è un parametro importante quando una voce deve essere registrata o riprodotta in un sistema elettroacustico.
Nota: il canto ad alto volume, misurato alle labbra, può raggiungere livelli di 130 dB re 20 μPa RMS e livelli di picco superiori a 150 dB re 20 μPa.
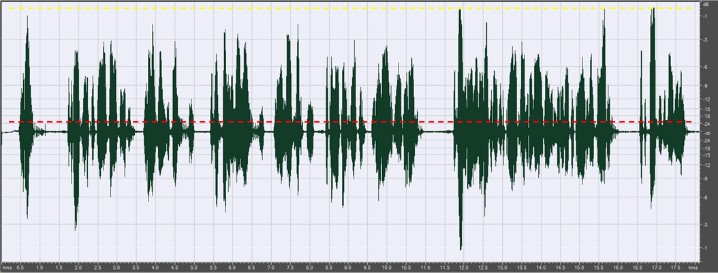
Voce maschile, parlato normale (durata 18 secondi). RMS medio: -21,5 dBFS, Picco: -0,5 dBFS. Fattore di cresta 11 (21 dB). La linea tratteggiata indica il livello RMS.
Lo spettro sonoro del discorso.
Lo spettro del discorso copre una parte molto ampia dello spettro di frequenze udibili completo. Nelle lingue non tonali, si può dire che il discorso consiste di suoni vocali e consonanti. I suoni voce sono generati dalle corde vocali e filtrati dalle cavità vocali. Un sussurro è senza suoni sonori.
Tuttavia, le cavità che contribuiscono alla formazione delle diverse vocali influenzano ancora il flusso d'aria che passa. Questo è il motivo per cui le caratteristiche dei suoni vocalici si verificano anche in un sussurro. In generale, la frequenza fondamentale del timbro vocale complesso, noto anche come pitch o f0, è compresa nell'intervallo 100-120 Hz per gli uomini, ma possono verificarsi variazioni al di fuori di questo intervallo. La f0 per le donne si trova all'incirca un'ottava più in alto. Per i bambini, f0 è di circa 300 Hz.
Le consonanti sono create da blocchi d'aria e suoni di rumore formati dal passaggio dell'aria attraverso la gola e la bocca, in particolare la lingua e le labbra. In termini di frequenza, le consonanti si trovano al di sopra di 500 Hz.
A una normale intensità vocale, l'energia delle vocali di solito diminuisce rapidamente al di sopra di circa 1 kHz. Si noti, tuttavia, che l'enfasi sullo spettro del discorso sposta da uno a due ottave verso frequenze più alte quando la voce si alza. Inoltre, si noti che non è possibile aumentare il livello sonoro delle consonanti nella stessa misura delle vocali. In pratica, ciò significa che l'intelligibilità della parola non aumenta con l'urlare, rispetto all'applicazione di uno sforzo vocale normale in situazioni in cui il rumore di fondo non è significativo.

Le formanti
Se ascolti due persone che parlano o cantano la stessa vocale allo stesso tono (f0), le vocali sono presumibilmente riconoscibili come identiche in entrambi i casi. Tuttavia, le due voci non producono necessariamente esattamente lo stesso spettro. Le formanti forniscono i suoni vocalici percepiti. Inoltre, le formanti forniscono informazioni diverse da chi parla a chi parla. Le formanti sono spiegate dal filtraggio acustico dello spettro generato dalle corde vocali. Le vocali sono create dalla "messa a punto" delle risonanze delle cavità nel tratto vocale.
2. Che cosa influenza l'intelligibilità?
Nelle lingue tonali come il cinese e il tailandese, gli oratori usano il tono lessicale o la frequenza fondamentale per segnalare il significato.
Nelle lingue non tonali come inglese, italiano, giapponese, ecc., Le parole si distinguono cambiando una vocale, una consonante o entrambe. Tuttavia, di questi due, le consonanti sono le più importanti.
Frequenze
importanti Le frequenze importanti nelle lingue non-tonali (occidentali) sono illustrate dal diagramma seguente. Qui, la banda di frequenza intorno a 2 kHz è la gamma di frequenza più importante per quanto riguarda l'intelligibilità percepita. La maggior parte delle consonanti si trova in questa banda di frequenza.

Uno spettro vocale è filtrato o passa-alto o passa-basso. L'utilizzo di un filtro HP a 20 Hz (in alto a sinistra) rende il parlato comprensibile al 100%. (Questo perché lo spettro vocale completo è lì). Un filtro HP che taglia tutto sotto i 500 Hz lascia comunque comprensibile il segnale vocale. Anche se la maggior parte dell'energia del discorso è tagliata, l'intelligibilità è ridotta solo del 5%. Tuttavia, l'applicazione di un cut-off più alto fa diminuire la comprensibilità.
Al contrario, l'applicazione di un filtro LP rende l'intelligibilità molto rapida. Quando si taglia a 1 kHz, l'intelligibilità è già inferiore al 40%. Si può vedere che la gamma di frequenza tra 1 kHz e 4 kHz è di grande importanza per l'intelligibilità.

Rumore di sottofondo
Il rumore di fondo influisce sull'intelligibilità percepita del segnale vocale. In questo caso, tutti i segnali diversi dal discorso stesso possono essere considerati rumore. Quindi in un auditorium o in una classe, l'aria condizionata e altre installazioni rumorose possono rendere il parlato meno comprensibile. Inoltre, la presenza di altre persone genera rumore. Nella TV o nel suono del film, è molto spesso una questione di relazione tra il livello del dialogo e il livello dei suoni di sottofondo musicale / atmosfera.
In questo diagramma, l'intelligibilità del parlato viene tracciata rispetto al rapporto segnale / rumore (S / N). La curva inferiore mostra che il parlato può essere ancora intelligibile in una certa misura anche se il S / N è negativo, il che significa che il rumore è 10 dB più forte del livello del parlato. Tuttavia, un livello del parlato percepito di circa 60 dB re 20 μPa è ottimale.
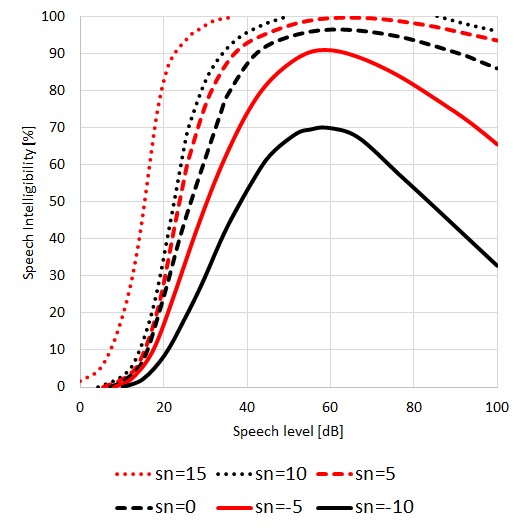
In questo diagramma l'intelligibilità del parlato è tracciata rispetto al rapporto segnale / rumore (S / N). La curva inferiore mostra che il parlato può ancora essere intelligibile in una certa misura anche se il S / N è negativo, il che significa che il rumore è 10 dB più forte del livello del parlato. Ma in ogni caso l'optimum è un livello di voce percepito intorno a 60 dB re 20 μPa.
Molte ricerche sono state condotte in questo settore. In generale, i risultati dimostrano che:
- Il livello di parlato ottimale è costante quando il livello di rumore di fondo è inferiore a 40 dB (A)
- Il livello di parlato ottimale sembra essere il livello che mantiene circa 15 dB (A) del rapporto S / N quando il livello di rumore di fondo è superiore a 40 dB (A)
- La difficoltà nell'ascoltare aumenta man mano che aumenta il livello del parlato nella condizione in cui il rapporto S / N è abbastanza buono da mantenere l'intelligibilità quasi perfetta
Inoltre, l'intervallo di frequenza 1-4 kHz dovrebbe essere "tenuto pulito". Quando, per esempio, aggiungendo la musica come sfondo per la narrazione, un equalizzatore parametrico che taglia la musica di 5-10 dB in questa gamma di frequenze migliorerà l'intelligibilità.
Riverbero.
Il riverbero è considerato rumore quando si parla di intelligibilità del parlato. Un piccolo riverbero può supportare il discorso, tuttavia non appena le consonanti vengono spalmate, l'intelligibilità diminuisce.
Direttività
Di seguito sono riportati grafici polari di oratori o speaker in entrambi i piani verticale e orizzontale. 

Modelli polari oratore umano. (rif .: Chu, WT, Warnock, AAC: Direttivita 'dettagliata dei campi sonori attorno agli oratori umani.)
Il livello tracciato e' ponderato in A e sia i maschi che le femmine sono tracciati in ogni diagramma. Tutti gli oratori erano seduti. I livelli sono stati misurati a 1 metro. Si può notare che la differenza tra fronte e retro è di circa 7 dB. Tuttavia, questo non fornisce alcuna informazione sulla dipendenza dalla frequenza: le alte frequenze attenuate più sulla parte posteriore rispetto alle frequenze più basse.
Si noti che nel piano verticale, il livello è più alto nella direzione di 330 ° rispetto ad altre direzioni. Questo è principalmente perché il suono viene riflesso dal petto.

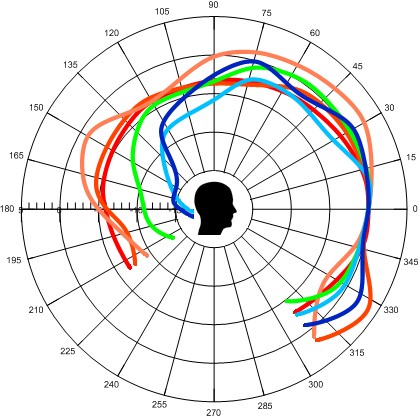
Questo diagramma mostra i diagrammi polari dipendenti dalla frequenza da 160 Hz a 8 kHz.
Si può vedere che la direttività aumenta da circa 1 kHz in su. Combinando questo fatto con l'importanza delle frequenze superiori a 1 kHz è ovvio che si ottenga una maggiore intelligibilità quando si registra di fronte anziché dietro la persona.
Parlanti umani, diagrammi polari intervalli di 1/3 di ottava. Divisione 5 dB (rif .: Chu, WT, Warnock, AAC: direttività dettagliata dei campi sonori attorno agli oratori umani).
Testa e petto
Nelle applicazioni broadcast e live sound, il microfono preferito è spesso un microfono lavalier (petto) o un microfono headset (headworn), che consente una maggiore libertà per l'utente. Uno dovrebbe essere consapevole del fatto che posizionare il microfono a questa breve distanza produce uno spettro registrato diverso dallo spettro naturale e neutro percepito ad una normale distanza di ascolto. Questa differenza è lungi dall'essere trascurabile.
La curva superiore quantifica il modo in cui lo spettro parlato raccolto al petto differisce dallo spettro del discorso della stessa persona rilevato a 1 metro. (Tutte le curve sono basate su misurazioni, in media 10 persone).
Dalle curve, si può vedere che c'è una tendenza generale di un aumento di circa 800 Hz che deve essere considerata compensata. Tuttavia, la deviazione più importante è l'attenuazione che causa una ridotta intelligibilità del parlato.
Va detto che il livello del discorso "all'angolo del tuo sorriso" è di circa 10 dB più alto rispetto alla posizione del torace.
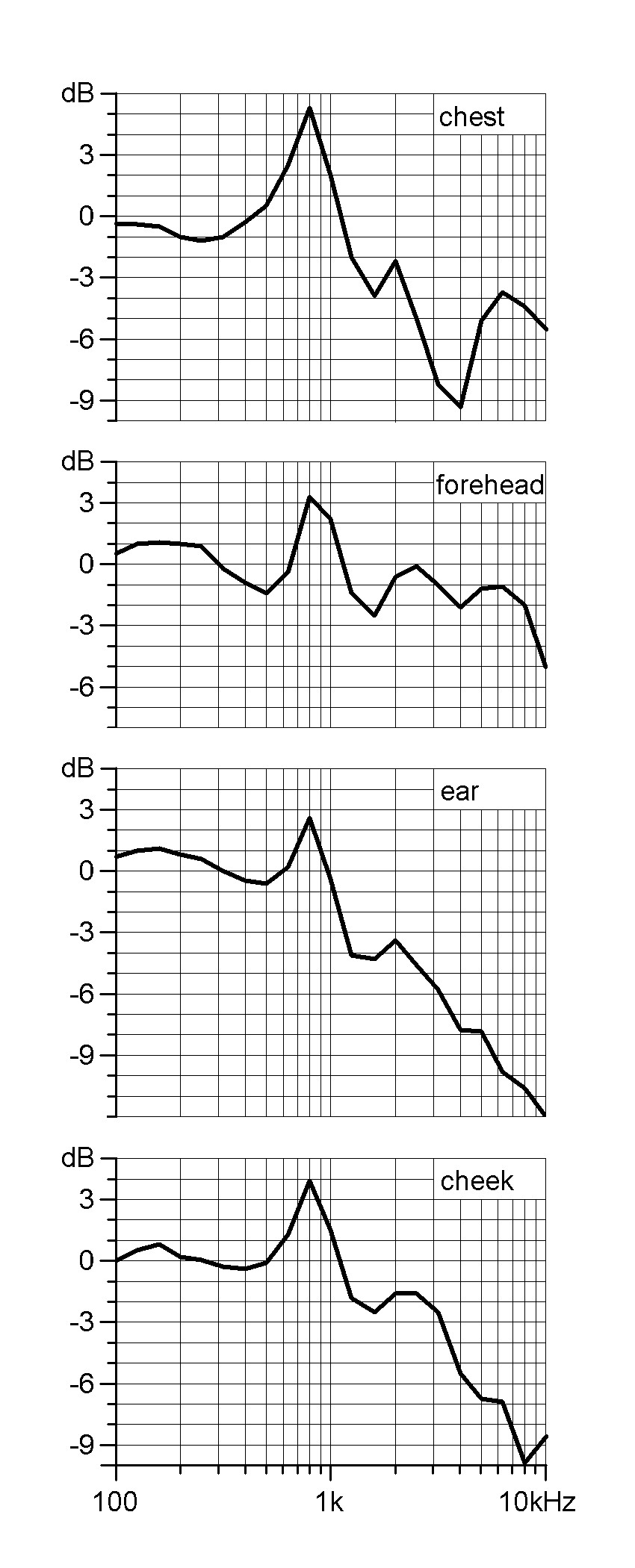
(Rif .: Brixen, Eddy B .: degradazione spettrale della parola catturata da microfoni miniaturizzati montati su teste e casse di persone, Convenzione AES n ° 100, Copenaghen, Danimarca, Preprint 4284.)
3. Posizionamento del microfono
A partire da queste condizioni, è possibile stabilire una serie di regole per la selezione e il posizionamento di un microfono ogni volta che l'intelligibilità del parlato è importante.
Microfoni palmari vocali
- I microfoni palmari vocali devono essere posizionati davanti alla bocca con un angolo di ± 30 °
- Se si utilizza un microfono direttivo (tipo cardioide o shotgun), dovrebbe essere indirizzato in asse (e non come un cono gelato)
- Un Antipop troppo denso può ridurre le frequenze più alte. Ricordati di compensare .
Microfono lavalier / a cravatta
Lo spettro del parlato nella tipica posizione del torace presenta una mancanza di frequenze nell'intervallo essenziale di 3-4 kHz. Se un microfono con una risposta in frequenza piatta è posizionato sul petto di una persona, il range di 3-4 kHz dovrebbe essere aumentato di circa 5-10 dB solo per compensare la perdita
- In pratica esistono due soluzioni: utilizzare un microfono pre-equalizzato per compensare o ricordare di effettuare la giusta equalizzazione nel processo di modifica. Notare che nessun mixer o telecamera ENG compensa automaticamente questo e non vengono forniti controlli per farlo. In molti casi, questo non viene mai compensato. Quindi, l'intelligibilità è spesso bassa
Microfono per cuffia
- Il livello del microfono dell'auricolare è di circa 10 dB più forte sulla guancia rispetto alla posizione del torace
- Lo spettro è meno influenzato rispetto alla posizione del torace. Tuttavia, in una certa misura, un roll off ad alta frequenza deve essere compensato
- La posizione della fronte (vicino all'attaccatura dei capelli), che viene spesso utilizzata nelle prestazioni cinematografiche e teatrali, è relativamente neutrale rispetto all'intelligibilità del parlato
Microfoni da podio
- I microfoni del podio sono spesso usati a varie distanze. Quindi, il microfono dovrebbe essere direttivo, specialmente nella gamma di frequenze superiore a 1 kHz
- Il microfono deve puntare alla bocca degli oratori
- I microfoni montati su podi non dovrebbero essere sensibili a vibrazioni o rumori di movimentazione
Ambiente rumoroso / riverberante
- Posiziona il microfono più vicino alla fonte sonora primaria (bocca di chi parla)
- Utilizzare un microfono con soppressione ad alto rumore, in genere un tipo cardioide / supercardioide.
Eddy B. Brixen - Audio Specialist



